
[Behind the CHIP 시즌2] 생명에서 발견한 반도체의 미래, DNA 컴퓨팅




1994년, 컴퓨터 과학자인 레너드 애들먼(Leonard Adleman)은 컴퓨터가 아닌 작은 시험관을 이용해 수학 문제를 푸는 전례 없는 실험에 도전했다. 그가 선택한 문제는 ‘해밀턴 경로 문제(Hamiltonian Path Problem)’였다. 이 문제는 여러 도시(꼭짓점)와 도시 사이를 잇는 일방통행 도로(연결선)로 구성된 도표에서, 주어진 출발 도시에서 시작해 도착 도시까지 모든 도시를 단 한 번씩만 거치는 경로를 찾는 것이다. 도시의 수가 늘어날수록 가능한 경로의 수가 기하급수적으로 증가하기 때문에, 해밀턴 경로 문제는 기존 컴퓨터로는 효율적으로 해결하기 어려운 난제로 여겨져 왔다.
시험관 속 다양한 DNA 조각과 효소가 혼합된 액체로 이루어진 애들먼의 실험은 겉보기엔 단순한 생물학 실험처럼 보였지만, 실제로는 전통적인 계산 방식의 한계를 넘어서는 과감한 시도였다. 이후 ‘DNA 컴퓨팅(DNA computing)’이라는 새로운 연구 분야의 탄생을 알리는 획기적인 사건으로 평가받고 있다.
생명의 언어, 계산의 도구가 되다
DNA는 아데닌(Adenine), 티민(Thymine), 구아닌(Guanine), 시토신(Cytosine)이라는 네 가지 염기로 구성된 생명의 언어다. 이 염기들은 일정한 규칙에 따라 짝을 이루는데, 아데닌은 티민과, 구아닌은 시토신과 정확하게 결합한다. 퍼즐 조각처럼 맞물리는 이 구조는 단순히 정보를 저장하는 기능을 넘어, 생화학 반응을 통해 새로운 정보를 생성하는 연산 기능까지 가능하게 한다. 여기서 말하는 생화학 반응이란, 상보적인 염기쌍이 정해진 규칙에 따라 결합하고, 특정 효소가 DNA 조각을 잘라내거나 이어 붙이며 새로운 염기서열을 형성하는 과정을 말한다.
정보과학의 관점에서 보면 DNA는 정보를 표현하는 코드로 해석할 수 있다. DNA를 구성하는 네 가지 염기는 4진법의 기호처럼 작동하며, 길이가 n인 DNA 가닥은 4n개의 고유한 정보를 저장할 수 있다. 나아가, DNA는 연산 기능도 수행할 수 있다. 상보적인 염기서열 간의 결합, 효소에 의한 절단과 연결 등의 생화학 반응은 마치 논리 연산처럼 작동하기 때문이다. 애들먼은 이러한 DNA의 특성을 활용해 도표의 각 꼭짓점과 연결선을 특정 염기서열로 표현했다.

애들먼은 꼭짓점과 연결선을 모두 DNA로 변환한 후, 각각의 DNA 조각을 대량으로 합성해 하나의 시험관에 넣었다. 이들 사이에서는 상보적 염기끼리 결합하는 반응이 일어나며, 이 과정을 통해 다양한 꼭짓점의 조합, 즉 수많은 경로가 자발적으로 형성된다.
시험관 속 계산, 컴퓨터 개념을 재정하다
이론적으로, 시험관 내 DNA 조각들은 규칙에 따라 자발적으로 결합하면서 가능한 모든 경로가 한꺼번에 형성된다. 이후 애들먼은 이 중에서 문제의 정답이 될 수 없는 경로들을 단계적으로 걸러냈다. 먼저, DNA 조각의 길이를 기준으로 해밀턴 경로의 조건에 부합하는 가닥을 선별했다.
예를 들어, 도시가 7개일 경우, 해밀턴 경로를 나타내는 DNA는 7개의 꼭짓점과 6개의 연결선이 이어진 정확한 길이의 긴 DNA 가닥이어야 한다. 그는 ‘겔 전기영동’이라는 실험 기법을 이용해 DNA를 크기 별로 분리하고, 이 중에서 정해진 길이를 갖는 조각만 골라 다음 단계로 넘겼다.
하지만 길이가 맞는다고 해서 그것이 반드시 정답 경로는 아니다. 각 DNA 가닥이 모든 꼭짓점을 한 번씩 포함하고 있는지를 확인하기 위해, 애들먼은 각 꼭짓점에 해당하는 염기서열을 기준으로 하나씩 검증했다. 이때는 각 염기서열과 상보적인 DNA 조각을 자석 비드에 부착한 후, 해당 꼭짓점이 포함된 DNA 가닥만을 선택적으로 결합시켜 분리하는 방식을 사용했다.
이러한 과정을 반복하여 모든 꼭짓점이 포함된 경우만 남긴 뒤, 최종적으로 살아남은 DNA 가닥만이 해밀턴 경로의 조건을 모두 만족하는 정답 후보가 된다. 최종 단계에서는 남은 DNA를 PCR*로 증폭한 뒤, 염기서열을 분석해 실제로 어떤 경로를 나타내는지를 확인했다.
* PCR: 중합효소 연쇄 반응. 특정 DNA 서열을 대량으로 증폭하는 실험 기술
이 실험은 약 일주일에 걸쳐 진행되었으며, 반복적이고 세밀한 실험 절차가 요구되었다. 그러나 그 결과는 전 세계 과학계를 깜짝 놀라게 했다. DNA를 이용해 계산 문제를 해결할 수 있다는 사실을 직접 증명한 최초의 사례였기 때문이다.
이 실험이 갖는 의미는 단순히 문제를 풀었다는 데에 그치지 않는다. 애들먼이 보여준 가능성 자체가 하나의 혁명이었다. 단 하나의 시험관 안에는 수조 개에 달하는 DNA 분자가 존재할 수 있고, 이는 곧 그 안에서 수조 개의 계산이 동시에 이루어질 수 있음을 의미한다. 이는 기존 컴퓨터가 연산을 순차적으로 처리하는 방식과는 완전히 다른, 자연 기반의 병렬 처리 방식이다.
더욱이 DNA 연산은 에너지 효율 면에서도 탁월해, 일반 컴퓨터보다 훨씬 적은 에너지로 대량의 연산을 수행할 수 있다. 결국 애들먼의 실험은 단순한 수학 퍼즐을 해결한 사건이 아니라, 우리가 ‘컴퓨터’라고 여겨온 개념 자체에 근본적인 질문을 던진 사례였다. 정보가 저장되고, 정해진 규칙에 따라 조작될 수 있다면, 그것이 실리콘이든, DNA이든 그 자체로 계산을 수행하는 ‘컴퓨터’가 될 수 있음을 보여준 것이다.
DNA 컴퓨팅 연구 동향
애들먼이 일으킨 패러다임의 전환은 이후 생명 시스템의 원리를 공학적으로 활용하는 생체모방 기술(biomimicry)로 이어졌고, 기존의 실리콘 기반 반도체 설계에 새로운 방향을 제시하게 되었다. 특히 초고밀도 정보 저장과 초저전력 연산이라는 두 가지 기술적 과제를 동시에 수행할 수 있는 가능성에 이목이 집중되고 있다.
예컨대 DNA 기반 회로는 전통적인 ‘폰 노이만 아키텍처(Von Neumann Architecture)*’와 달리, 메모리와 연산 장치가 구분되어 있지 않다. 오히려 우리의 뇌처럼 데이터를 처리하면서 동시에 저장하는 구조를 갖는다. 이러한 방식은 복잡한 연산을 병렬로 수행하고, 다양한 입력 신호를 실시간으로 처리하는 데 있어 매우 효율적인 가능성을 열어준다.
* 폰 노이만 아키텍처(Von Neumann Architecture): 현대 컴퓨터의 기본 구조로, 메모리와 연산 장치가 분리되어 순차적으로 데이터를 처리하는 방식
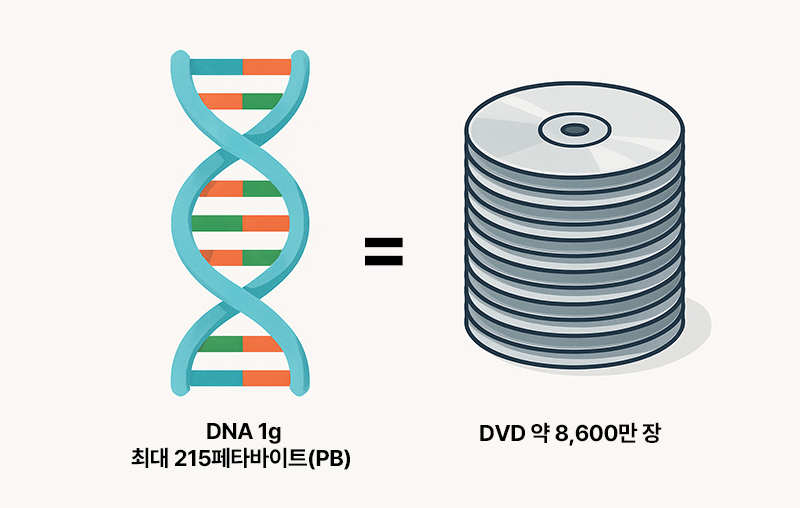
또한 DNA는 실리콘 기반 반도체가 쉽게 따라갈 수 없는 압도적인 정보 밀도를 자랑한다. 예를 들어 DNA 1그램에는 최대 215페타바이트(PB), 즉 약 2억 1500만 기가바이트(GB)의 데이터를 저장할 수 있으며, 이는 DVD 약 8,600만 장에 해당하는 분량이다. 이처럼 DNA는 작은 부피에 방대한 정보를 담을 수 있을 뿐 아니라, 전력 소비 없이도 장기간 안정적으로 정보를 보존할 수 있어 친환경적이고 지속 가능한 미래 기술로 주목받고 있다.
2020년, 하버드대 조지 처치(George Church) 교수 연구진(고려대 천홍구 교수 공동 참여)은 효소와 자외선을 활용해 빛으로 DNA를 인쇄하듯 합성하는 새로운 기술을 개발했다. 이들이 사용한 TdT(Terminal deoxynucleotidyl Transferase)라는 DNA 합성 효소는 특정 금속 이온이 존재할 때에만 작동하는데, 연구진은 해당 이온을 ‘숨긴(caged)’ 상태로 보관하다가 자외선을 특정 위치에 조사함으로써 이온이 방출되고, 그에 따라 효소가 활성화되도록 설계했다.
이 방식은 기존의 생화학 반응 기반 DNA 합성과는 달리, 여러 가닥의 DNA를 동시에 병렬적으로 합성할 수 있다는 점에서 정밀성과 효율성 두 측면에서 획기적인 진보를 이룬 것으로 평가된다. DNA를 차세대 정보 저장 매체로 활용하려는 연구에 있어, 기술적 전환점을 마련한 성과라 할 수 있다.
이처럼 DNA를 초고밀도 디지털 저장 장치로 활용하려는 가능성은 점차 현실에 가까워지고 있다. 하지만 여전히 남아 있는 과제가 하나 있다. 바로, DNA에 저장된 정보를 얼마나 정확하게 복원할 수 있는가에 대한 문제다.
이에 대해 2025년, 중국 상하이 교통대학교 연구진은 핵심적인 해결책으로 ‘MPHAC-DIS(Massively Parallel Homogeneous Amplification of Chip-scale DNA for DNA Information Storage)’ 기술을 발표했다. 다소 복잡하게 느껴지는 이 명칭 속에는, 기술의 핵심 원리가 고스란히 담겨 있다.
기존의 PCR 기반 DNA 증폭 방식은 DNA 조각에 동일한 길이의 ‘프라이머(primer)’를 적용했지만, DNA 조각마다 상이한 열역학적 특성을 충분히 고려하지 못해 증폭 효율에 편차가 발생하고, 이로 인해 정보의 왜곡이나 손실이 초래되곤 했다.
이에 반해 ‘MPHAC-DIS’는 각 DNA 조각의 결합 특성과 자유 에너지(ΔG°)를 기반으로 정밀하게 설계된 맞춤형 프라이머를 적용함으로써, 모든 DNA 조각이 균일하게 증폭될 수 있도록 했다. 그 결과, 정보의 편중 없이 고르게 복원하는 것이 가능해졌으며, 이는 DNA 기반 저장 기술의 신뢰성과 정확성을 비약적으로 향상시켰다는 평가를 받고 있다.
실제로 연구진은 해당 기술을 활용해 텍스트, 이미지, 영상 등 다양한 디지털 파일을 DNA에 저장하고 이를 성공적으로 복원하는 데에 성공했다. 특히 일부 손상된 데이터에 대해서는 인공지능(AI) 기반의 이미지 복원 기술을 접목해 시각적으로도 고품질의 결과를 구현했다.
이러한 일련의 기술 발전은 머지않아 우리가 감상하는 영화, 촬영한 사진, 작성한 문서와 같은 디지털 자산들이 더 이상 실리콘 칩이 아닌, 수십억 년 동안 생명 정보를 품어온 DNA 분자 속에 저장되는 시대의 도래를 예고하고 있다.

DNA를 이용한 정보 저장 기술은 현재 암호화, 질병 진단, 데이터 분석 등 다양한 분야에서 빠르게 발전하고 있다. 예를 들어, DNA 서열을 무작위로 재배열하는 ‘DNA 셔플링(shuffling)’, 특정 정보를 서열 내에 삽입해 원본성과 출처를 증명하는 ‘DNA 워터마킹(watermarking)’ 기술은 높은 수준의 데이터 보안과 디지털 저작권 보호 수단으로도 주목받고 있다. 이처럼 생명의 언어인 DNA는 이제 연산, 저장, 보안까지 아우르는 차세대 정보 기술 매체로 진화하고 있다.
물론, 아직 극복해야 할 과제도 존재한다. DNA 컴퓨팅은 느린 연산 속도와 높은 비용이라는 두 가지 한계를 안고 있다. DNA의 생화학 반응은 실리콘 칩의 전자 신호만큼 빠르지 않고, 염기서열의 합성과 분석에도 상당한 시간과 자원이 소요된다. 그러나 지금까지의 연구는 그 한계 너머의 가능성을 끊임없이 증명해왔다. DNA는 단순한 저장 매체를 넘어, 임상 진단, 클라우드 시스템, 인공지능 회로와 같은 복합적인 정보 처리 기술로 진화하고 있으며, 그 응용 범위는 점점 더 넓어지고 있다.
우리는 지금, 생명의 언어가 기술의 언어로 새롭게 쓰이기 시작하는 전환점에 서 있다. 미래의 반도체가 반드시 실리콘일 필요는 없다. 생명 정보를 품고 있는 이 작은 분자가, 머지않아 인류의 기술까지 담아낼 준비를 하고 있다. 돌이켜보면, 인류의 삶을 한 단계 도약시킨 위대한 과학적 성취 대부분은 호기심에서 비롯된 자유로운 탐구에서 시작되었다. 알베르트 아인슈타인은 제약 없는 상상력의 가치를 강조하며 다음과 같은 말을 남겼다.
“상상력은 지식보다 중요하다. 지식은 우리가 아는 것에 머물지만, 상상력은 그 너머의 세상까지 펼쳐 보인다(Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world)”

DNA라는 생명의 언어를 향한 상상은 지금, 기술의 미래를 여는 또 하나의 언어로 번역되고 있다. 그 상상은 아직 낯설고 생소하지만, 언제나 그래왔듯 미래는 그런 낯선 질문에서부터 시작된다. 그리고 언젠가, 우리가 품었던 그 상상은 지식이 되고, 기술이 되고, 삶이 될 것이다.
비하인드 더 칩 시즌2, 비하인드더칩시즌2, Behind the CHIP, 비하인드더칩, 비하인드 더 칩, 김응빈, 김응빈 교수
※ 본 칼럼은 외부 필진의 견해로, 삼성전자 DS부문의 공식 입장과 다를 수 있습니다.


